Training Agents¶
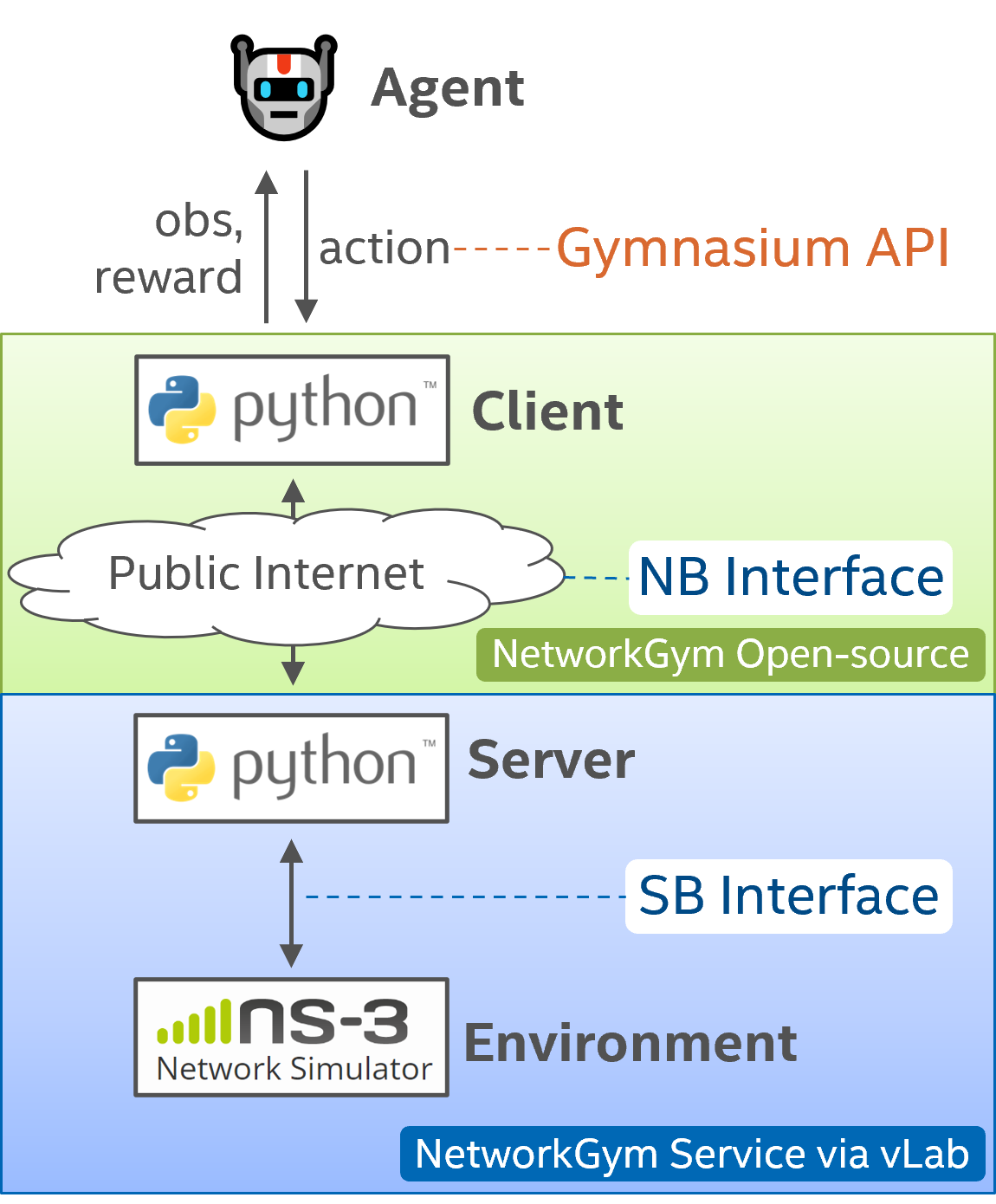
NetworkGym provides a range of network agents, each designed to fulfill specific roles when interacting with NetworkGym Environments.
System Default Agent¶
The System Default Agent enables the collection of data for offline training purposes. To activate system default algorithms, a agent simply sends an “empty” action to the environment. You can use the demo code and modify the action as shown below:
# action = env.action_space.sample() # agent policy that uses the observation and info
action = np.array([]) # No action from the RL agent will trigger the system default algorithm provided by the environment.
Custom Algorithm Agent¶
NetworkGym offers flexibility by allowing users to define their own specialized agents by using the Gymnasium’s API. Refer to the Gymnasium’s tutorial for detailed instructions on creating custom agents.
Stable-Baselines3 Agent¶
The Stable-Baselines3 Agent includes the State-of-the-Art (SOTA) Reinforcement Learning (RL) algorithms sourced from stable-baselines3. These algorithms include popular ones such as PPO (Proximal Policy Optimization), DDPG (Deep Deterministic Policy Gradient), SAC (Soft Actor-Critic), TD3 (Twin Delayed Deep Deterministic Policy Gradient), and A2C (Advantage Actor-Critic). Moreover, these algorithms have been integrated to seamlessly interact with the NetworkGym Environment.
CleanRL Agent¶
A CleanRL Agent is available for custom algorithms.